
No replication crisis in fruit-fly immune system research
A large-scale, systematic review shows the majority of research claims in this field holds up to further scrutiny.
Much has been made of the Replication Crisis, which is the notion that results of modern science frequently cannot be replicated. What is often missing from the discussion, however, is the extent to which success or failure of replication can be field-dependent. The concept of a replication crisis has its origin in psychology, which seems to suffer from severe issues of lack of reproducibility. Biomedical research is also frequently brought up as suffering from reproducibility, though notably these statements are based on a small number of reproducibility studies evaluating primarily a very narrow sliver of biomedical research, pre-clinical cancer studies. My own research is in protein biochemistry and I don’t have the sense that this field suffers strongly from issues of reproducibility. That is a personal opinion though. Hard data would be preferable.
A set of two recent papers greatly expands our perspective on reproducibility in biomedical research. These papers systematically evaluate an entire field, research into the immune system of the fruit fly Drosophila. This is a research field with a long history, and so the authors were able to take studies published before 2012 and assess how claims have held up over the years since. They evaluated 400 studies published between 1959 and 2011 and containing over 1000 distinct scientific claims. For each claim, the authors determined whether it was subsequently verified, challenged, or not further investigated. This analysis involved mostly reviewing the existing literature but also performing some additional experimental tests for a subset of claims.
The first paper contains the results from this extensive review:
Westlake et al. (2025) Reproducibility of Scientific Claims in Drosophila Immunity: A Retrospective Analysis of 400 Publications. bioRxiv, doi:10.1101/2025.07.07.663442.
Unless you are deeply interested in Drosophila immunity, you probably don’t need to read this paper. It just goes through all the scientific claims and explains whether they held up to further scrutiny or were ultimately challenged.
For a general audience, the second paper is more interesting:
Lemaitre et al. (2025) A retrospective analysis of 400 publications reveals patterns of irreproducibility across an entire life sciences research field. bioRxiv, doi:10.1101/2025.07.07.663460.
It takes the findings from the first paper and identifies trends, such as how many claims were verified versus challenged, what are the characteristics of the authors who made those claims, and so on. Here, I want to go through some of the key findings of the second paper.
First, and most importantly, despite the wording of the title (“patterns of irreproducibility”) the overarching message is that the vast majority of claims (61%) held up to further scrutiny and could be verified. Only 6.9% of claims were successfully challenged. I think this result is quite comforting. The vast majority of research in this field appears to be reliable. And having some proportion of scientific claims not hold up to further scrutiny is totally normal and expected. Science is about building new knowledge, and we can’t expect it to be always right on first try. Sometimes we make mistakes, or we confuse ourselves, or we over-interpret a result, and all of this is acceptable as long as it’s not done deliberately and with the intent to deceive. In fact, there have been occasions in the history of science where an incorrect claim has spawned extensive follow-up research that ultimately moved the field forward. Nothing motivates researchers like the opportunity to invalidate a bold claim by a famous scientist. (Hold this thought. We’ll get back to it.)
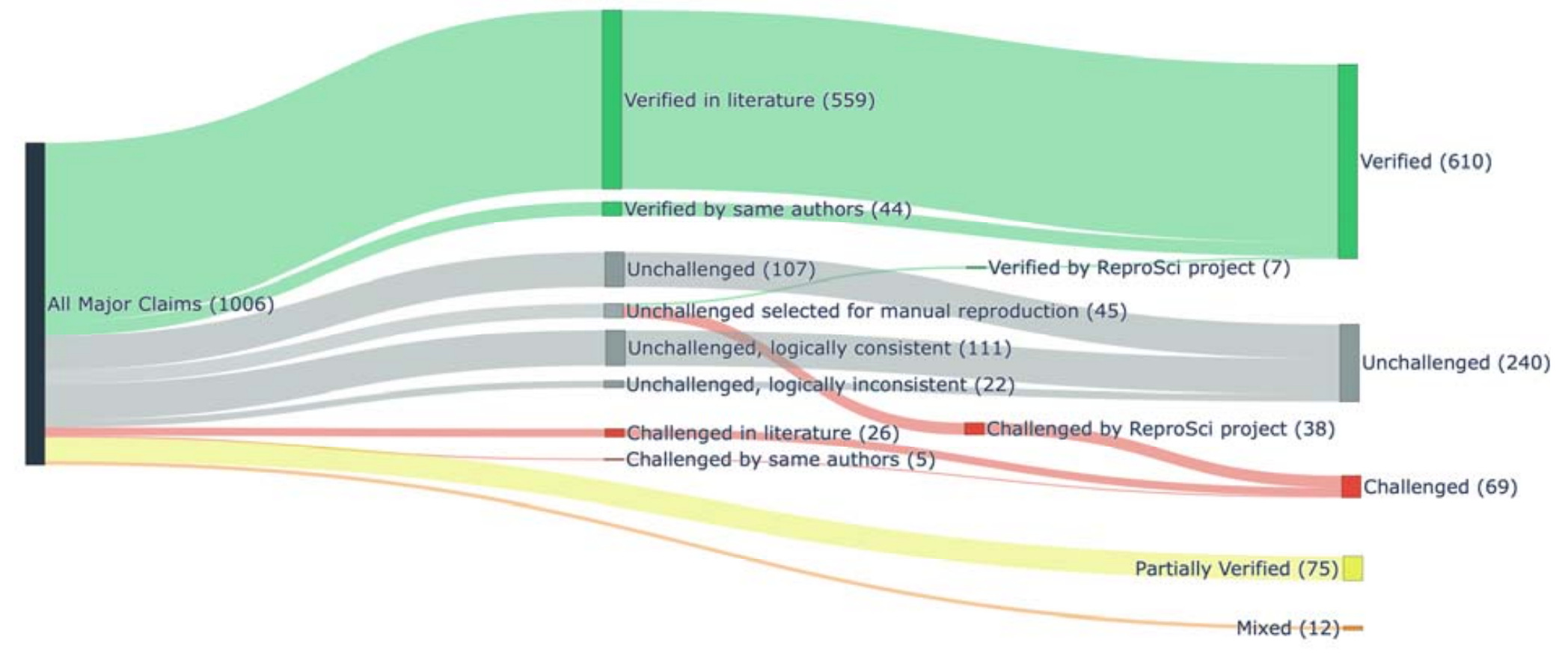
It is noteworthy that the majority of the challenged claims came from the additional experimental effort by this project, which chose 45 unchallenged claims, experimentally tested them, and found that 38 could not be verified. (Compare this to only 31 claims that had been challenged in the existing literature.) We might be tempted to interpret this finding as implying that most of the remaining unchallenged claims would likely fail verification if they were subjected to it. However, I am a bit wary of this conclusion. We don’t know how claims were chosen for additional experimental testing. Did they choose claims they thought were particularly unlikely to verify, or alternatively those they thought would hold up, or did they choose at random? An expert in the field would certainly be able to assess the likelihood that a given claim could or could not be verified. In fact, the authors identify subsets of unchallenged claims that are either consistent (“unchallenged, logically consistent”) or at odds (“unchallenged, logically inconsistent”) with other known facts in the field. I would expect that the latter category of claims is more likely to fail verification. I don’t think this was systematically studied.
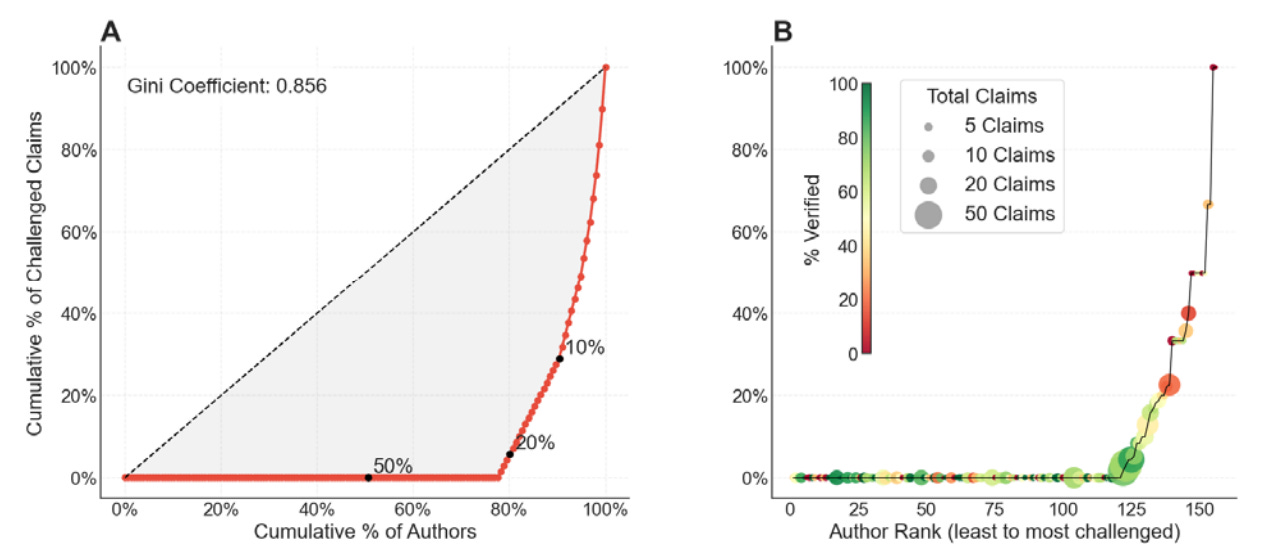
Having a long list of verified or challenged claims, we can ask how the different types of claims are distributed across authors, both first authors and senior authors. The results are roughly the same for both: Approximately 80% of authors don’t have a single challenged claim. The challenged claims are concentrated in a small subset of authors. This may indicate that some labs or authors work to lower standards than others, but keep in mind that there are approximately ten times more verified than challenged claims. If you just randomly distributed claims across authors you’d end up with many authors that didn’t have any challenged claims. So even if all labs worked to the same standards and tried to do their best publishing reliable science, I think you’d still end up with a highly skewed distribution. In fact, the fewer unreliable claims published the more they’d be concentrated on a small proportion of authors.
The final analysis from this work that I’d like to highlight is a statistical analysis of whether there are any factors that could reliably predict an increased or reduced number of challenged claims. Surprisingly, virtually none of the factors considered had an effect, except the ranking of the university. Studies from universities that were ranked in the top 50 according to the Shangai University Rank had a significantly increased likelihood to contain challenged claims, compared to studies from other universities.
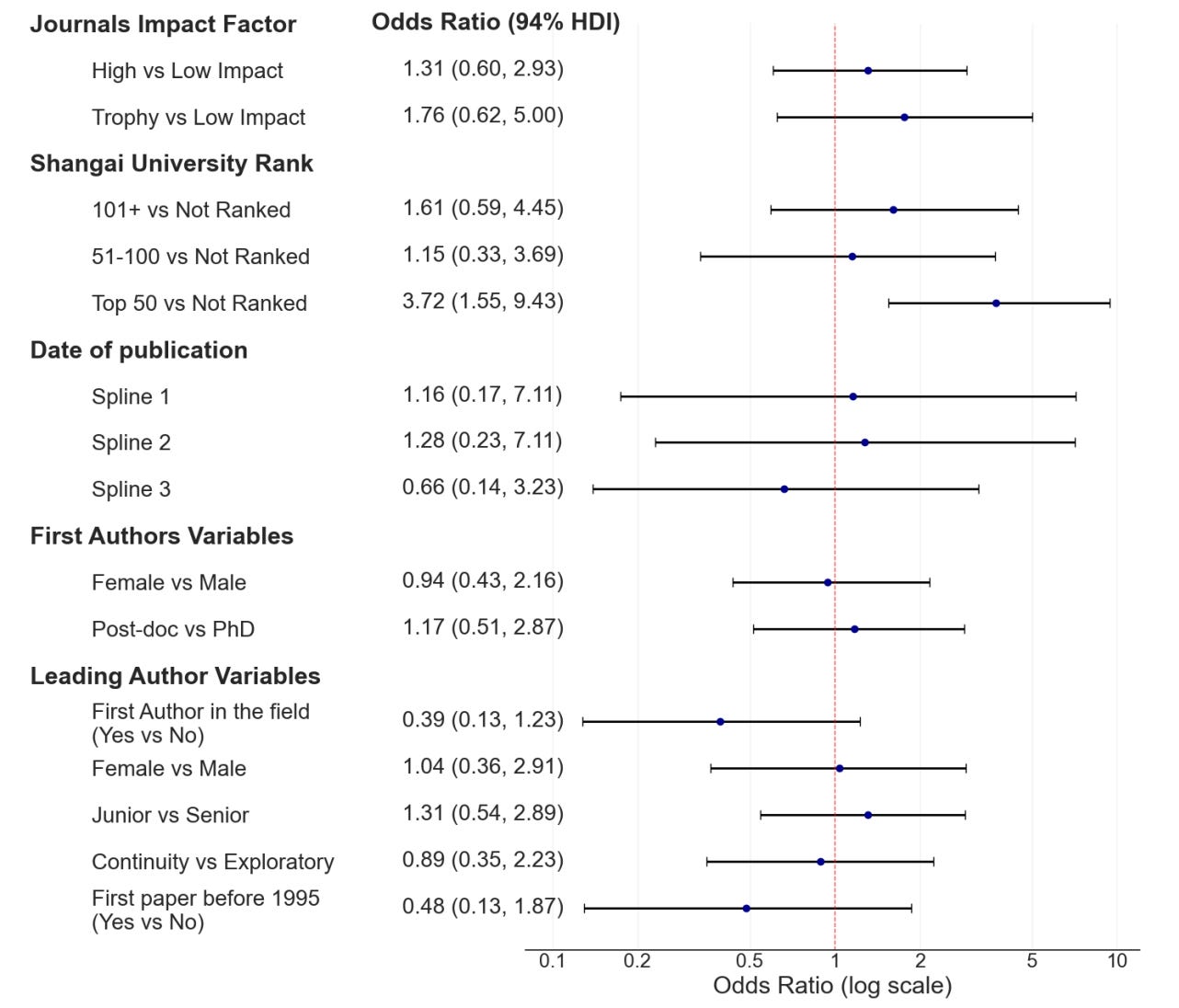
One could be tempted to interpret this as implying that higher ranked universities produce lower quality work, but I think this is a simplistic perspective that is not supported by the analysis. Remember that many more claims are unchallenged than challenged. For a claim to end up challenged, somebody needs to care enough that they redo the experiment. It is likely that work from the higher-ranked universities is more commonly subjected to subsequent verification, and therefore ends up more commonly on the list of successfully challenged works.1 This is where we return to the idea that many scientists are highly motivated to disprove their most famous peers.
In summary, this collection of two papers is a valuable contribution to the field of scientific reproducibility. I’m not an expert in Drosophila immunity, but as far as I can tell this effort is very well done and carefully documented. There is a website where claims are being tracked and members of the community can contribute. I think this effort can serve as a template for future reproducibility efforts in other research fields.
And let’s emphasize one more time that over half of the challenged claims were due to the additional efforts by this project. So knowing how claims were chosen for subsequent verification is critical for properly interpreting the statistical findings.